Blog | Git Repositry | Download |
The uSpeech library provides an interface for voice recognition using the Arduino. It currently produces phonemes, often the library will produce junk phonemes. Please bare with it for the time being. A noise removal function is underway. It can classify phonemes.
Computer scientists would call it a “feature extraction” toolkit for voice recognition of entire words or sentences. As such it does not have any way of classifying the features of a word. That is left for the user to implement and therefore it can be a bit difficult to use the library.
Minimum Requirements
The library is quite intensive on the processor. Each sample collection takes about 3.2 milliseconds so pay close attention to the time. The library has been tested on the Arduino Uno (ATMega32). Each signal object uses up 180bytes. No real time scheduler should be used with this.
Features
- Letter based recognition
- Small memory footprint
- Arduino Compatible
- Fixed point arithmetic (not anymore)
- 30% – 40% accuracy if based on phonemes, up to 80% if based on words.
- Plugs directly into an
analogRead()port
Documentation
Head over to the wiki and you will find most of the documentation required. Doxygen manual is available here.
Installation
Download the source code from github. Then read installation section of the wiki.
Latest News: @Pyrohaz has ported µspeech to STM32F0, for those interested take a look at his blog: http://hsel.co.uk/2016/01/06/stm32f0-uspeech-port/ !
Algorithm
The library utilizes a special algorithm to enable speech detection. First the complexity of the signal is determined by the following formula:
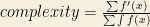
Consonants (other than R,L,N and M) have a value above 40 and vowels have a value below 40. Consonants, they can be divided into fricatives and plosives. Plosives are like p or b whereas fricatives are like s or z. Generally each band of the complexity coefficient (abs derivative over abs integral) can be matched to a small set of fricatives and plosives. The signal determines if it is a plosive or a fricative by watching the length of the utterance (plosives occur over short periods while fricatives over long). Finally the most appropriate character is chosen.
Contributing
Documentation in other languages are welcome. I will be translating to spanish and chinese (simplified) but the more the merrier. Have a look at the following sections before doing anything:
To get started hacking on this project you should make all changes to the 4.x-workingBranch.

7 replies on “µSpeech”
phantastic work! do you have any recommendation concerning hardware? i’d guess a plain microphone is too weak signalwise, i.e. there should be a pre-amp. any other considerations?
I got the volume and mic power working but when I tried to configure the coef I get no numbers back. Any ideas what to try first?
Hi Mr. Price, Im not sure exactly what the reason for this is. Have you checked which version you downloaded?
Latest stable release v4.1.1
Is the most stable and bug-free release so far. v4.2 has issues with the
debug_uspeechsketch as detailed here. If you still have trouble email me at:a r j o 129 at gmail.com
(ignore the spaces)
Great job u doing with Uspeech….I am working on Arduino Uno R3 and very impressed with your work….and will use your uSpeech in my Project……(if its ok with u)
my project needs to control relays based on voice commands like “relay 1 on” “relay 2 off”
hence I was considering that you must have something to help me out…….
please buddy help me out…..
plus my deadline is super close……
email=amanchetry41@gmail.com
thank you
can you please give me the Phonems for “Forward, Backward and Stop” ?
Hi Arjo,
I’ve recently coded a port of your uSpeech library for the STM32F0 Discovery board (http://hsel.co.uk/2016/01/06/stm32f0-uspeech-port/).
I hope you have no issue with my having written a port for the STM32F0 but if you do, feel free to get in contact with me and I will take it down!
Keep up the good work,
Harris
How to recognize words using this library?