TL; DR — Many languages have a lot of similar words. These similarities often times relate to similarities arising due to trade, empires and human migrations. I built an open source tool to automatically detect and visualize their similarities. The tool is in its infancy — its not perfect.
Having grown up in a multicultural environment, one of the things that one gets exposed to is a variety of languages. As a child I first learned to speak English and Bengali simultaneously as those are the languages that my family spoke at home. Subsequently through kindergarten, primary school and secondary schooling I learned Mandarin. During my high school years I also learned Spanish. Having learned all these languages I often found that there were uncanny similarities between certain words in languages. Much of the human languages that we speak are made up of cognates and loanwords. These words reflect certain deep historical relationships between cultures and people.
Take the word “tea” for instance. If you were to look around the world, there are essentially only two pronunciations — “cha” and “teh”. If you were to try to visualize this using a map you would get something like this:

The swathe of pink represents the languages in which tea is based on the pronunciation “cha”. In Greek and Tagalog it seems that the word “tsai” is used and the other colors represent languages in which some variant of “teh” is used. If you notice something interesting, languages which are more inland tend to use the pronunciation “cha”. The reason for this is simple:

Tea originated in China. However, traders used to use two routes to bring goods out of China: one over land and one over the sea. The traders on the sea route would buy tea from Chinese in south China who spoke dialects like Hokkien in which tea was pronounced “teh” versus those cultures which imported it via the land based routes which passed through northern China adopted the Mandarin pronunciation of “cha”.
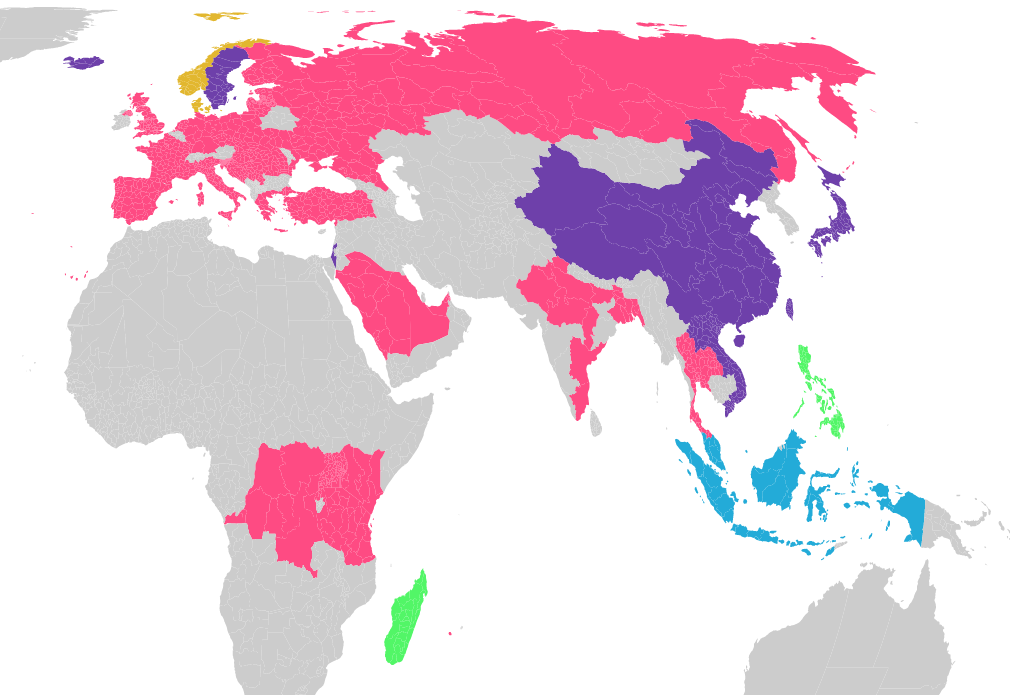
There are many more words which have similar stories. Take the number “seven” for instance. A map of pronunciations looks like this:

Here we see a huge swathe of pink — most of these matches are due to a common Indo-european root “*septḿ̥” [2]. Not all of this is valid as the tool I’ve developed to generate these maps is not perfect. As noted some of them are false positives. However, many of the matches are valid. For instance, the green match between Philippines and Madagascar is actually real! Malagasy, the language spoken in Madagascar belongs to the same family as Tagalog, Indonesian and Malay. The Malagasy people do have shared genes with the people of the Malay Archipelago at some point the early settlers of the Malay peninsula actually sailed across the Indian Ocean to intermingle with the local population [3]. It is interesting to see how this can be captured through common words in the language. Furthermore, whats more interesting is the fact that we can automatically detect these using a computer!
So how are we generating these maps?
The maps you see above have been generated using a tool I built some time ago. The live version of the tool lives here. It is an interactive tool but takes about 1 minute to get all the translations. The tool itself is currently reliant on the Microsoft Translate/Transliterate API. Once the tool gets a transliteration of the word that has been queried it calculates the edit distance between the transliterations (I’ve tried soundex and — no it doesn’t give good results). Once the edit distances have been calculated and normalized, they are run through the DBSCAN algorithm to perform clustering. The current version as of this blog post performs a hyperparameter search and tries to find the “best” hyperparameters for DBSCAN. This part still needs some work as it is far from perfect. The tool is written in Python and lives in an azure cloud function. The code is available here.
There are many more interesting stories that link us waiting to be found in the etymology of various words. Feel free to poke around yourself and see what you find.
Sources:
[1] https://qz.com/1176962/map-how-the-word-tea-spread-over-land-and-sea-to-conquer-the-world/
[2] https://en.wikipedia.org/wiki/Proto-Indo-European_language
